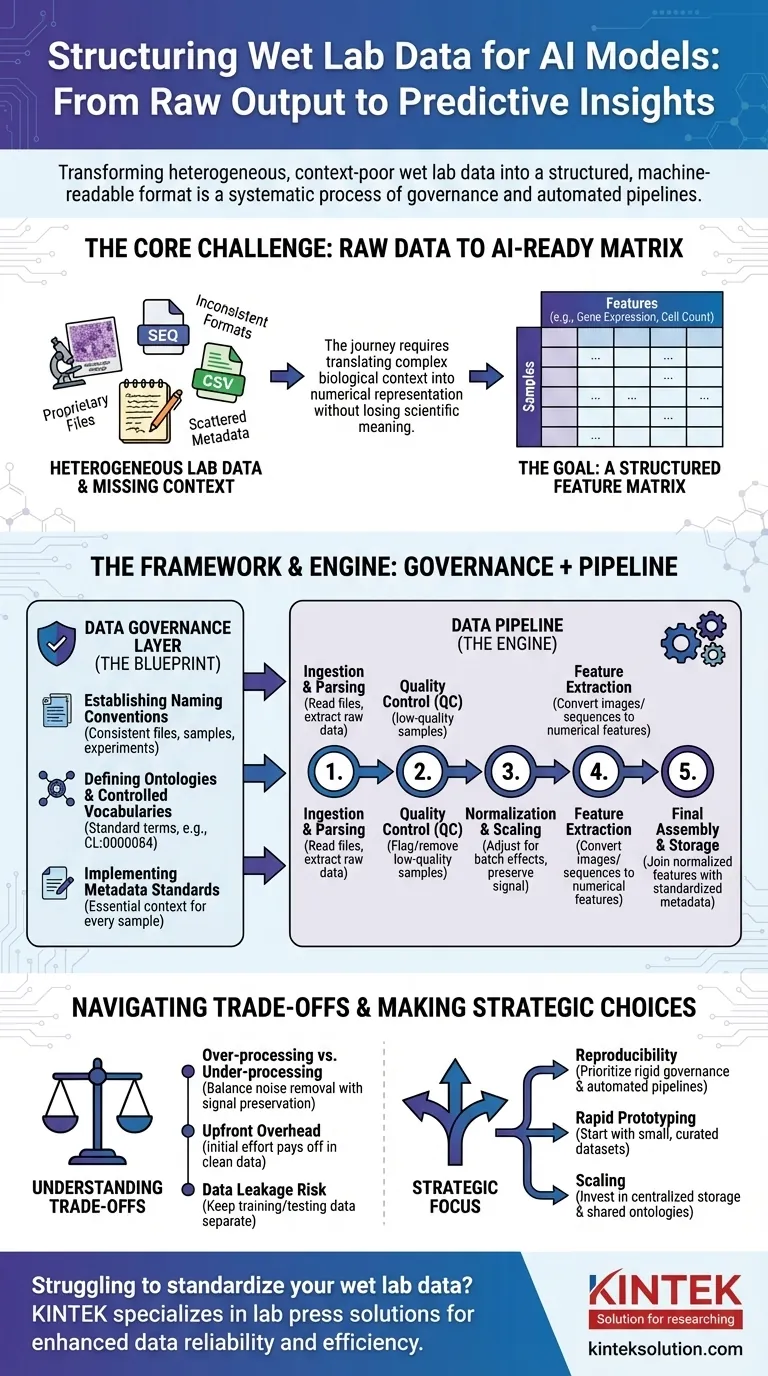
Para preparar dados de laboratório úmido para IA, você deve transformá-los de seu estado bruto, muitas vezes inconsistente, em um formato estruturado e legível por máquina. Este não é um passo único, mas um processo sistemático que envolve governança de dados para criar regras claras, seguido por pipelines de dados que automatizam a limpeza, normalização e estruturação dos resultados experimentais brutos em um formato consistente adequado para o treinamento de modelos.
O desafio central não é simplesmente reformatar arquivos. Trata-se de traduzir sistematicamente o contexto biológico complexo — como condições experimentais, histórico da amostra e técnicas de medição — em uma representação numérica estruturada que um modelo de IA possa aprender sem perder o significado científico crítico.

O Problema Central: De Saída Bruta a Dados Prontos para IA
A jornada da bancada do laboratório a um modelo preditivo está repleta de desafios de dados. A saída bruta de instrumentos científicos raramente, ou nunca, está pronta para uso direto em um algoritmo de IA.
A Heterogeneidade dos Dados de Laboratório
Os dados de laboratório úmido vêm em uma vasta gama de formatos. Isso inclui tudo, desde arquivos proprietários de sequenciadores e microscópios até CSVs simples de leitores de placas, cada um com sua própria estrutura e peculiaridades.
Um modelo de IA, no entanto, requer um formato unificado.
A Maldição do Contexto Ausente
Informações críticas, ou metadados, são frequentemente dispersas. Pode estar no caderno de um cientista, em uma planilha separada ou simplesmente em sua cabeça. Sem esse contexto (por exemplo, qual medicamento foi aplicado, a temperatura, a linhagem celular utilizada), os dados numéricos são sem sentido.
O Objetivo: Uma Matriz de Características
Em última análise, a maioria dos modelos de IA precisa de dados em uma matriz de características. Esta é uma tabela simples onde as linhas representam amostras individuais (por exemplo, um paciente, um poço de cultura de células) e as colunas representam características (por exemplo, níveis de expressão gênica, medições de morfologia celular, concentrações de proteínas).
Uma Estrutura para Padronização: A Camada de Governança de Dados
Antes de poder construir pipelines automatizados, você deve estabelecer regras. Esta é a governança de dados — o projeto que garante a consistência em todos os experimentos e equipes. É a etapa mais crítica e frequentemente negligenciada.
Estabelecendo Convenções de Nomenclatura
Uma regra simples, mas poderosa, é impor um esquema de nomenclatura consistente para arquivos, amostras e experimentos. Isso permite que os dados sejam vinculados e rastreados programaticamente desde sua origem até a análise final.
Definindo Ontologias e Vocabulários Controlados
Uma ontologia fornece um conjunto padrão de termos para descrever entidades biológicas. Por exemplo, em vez de permitir "célula T", "linfócito T" e "Tcell", um vocabulário controlado impõe um único termo, como CL:0000084 da Ontologia Celular.
Isso evita ambiguidades e garante que dados de experimentos diferentes sejam verdadeiramente comparáveis.
Implementando Padrões de Metadados
Você deve definir os metadados mínimos que devem ser capturados para cada amostra. Isso geralmente inclui a fonte da amostra, as condições experimentais, as configurações do instrumento e a data. Esta regra garante que nenhum ponto de dado se torne um órfão, separado de seu contexto.
O Motor da Transformação: Construindo o Pipeline de Dados
Com as regras de governança estabelecidas, você pode construir um pipeline de dados. Esta é uma série de etapas de software automatizadas que transformam dados brutos na matriz de características final pronta para IA.
Etapa 1: Ingestão e Análise de Dados
O primeiro trabalho do pipeline é encontrar e ler os arquivos de dados brutos. Esta etapa envolve a escrita de analisadores específicos para o formato de saída de cada instrumento para extrair as medições primárias e quaisquer metadados associados.
Etapa 2: Controle de Qualidade (CQ)
Nem todos os dados são bons dados. O pipeline deve sinalizar ou remover automaticamente amostras de baixa qualidade com base em métricas predefinidas, como baixa contagem de células em um experimento de imagem ou baixa qualidade de leitura de um sequenciador.
Etapa 3: Normalização e Escalonamento
As medições de diferentes lotes ou placas geralmente apresentam variações técnicas. A normalização é uma etapa crucial que ajusta os dados para tornar as medições comparáveis entre os experimentos, removendo ruído técnico enquanto preserva o sinal biológico.
Etapa 4: Extração de Características
Dados brutos geralmente não estão em formato de característica. Uma imagem, por exemplo, deve ser processada para extrair características numéricas como tamanho, forma e intensidade da célula. Uma sequência de DNA pode ser convertida em um vetor de frequência k-mer. Esta etapa transforma dados complexos em números que a IA pode usar.
Etapa 5: Montagem Final e Armazenamento
Finalmente, o pipeline une as características normalizadas com os metadados padronizados. Isso cria a matriz de características final e limpa, que é então salva em um formato estável e consultável (como Parquet ou um banco de dados) para treinamento de modelos.
Entendendo as Compensações
Estruturar dados não é um processo neutro. Cada escolha que você faz pode influenciar o desempenho e a interpretação do modelo final.
Superprocessamento vs. Subprocessamento
A normalização ou filtragem agressiva pode, às vezes, remover sinais biológicos sutis, mas importantes. Por outro lado, falhar em remover o ruído técnico garantirá que seu modelo aprenda com artefatos experimentais em vez de biologia. Este é um equilíbrio constante.
A Padronização Cria Sobrecarga Inicial
A implementação da governança de dados requer um esforço inicial significativo e o envolvimento de toda a equipe. Pode parecer que desacelera a pesquisa no início, mas paga dividendos enormes ao evitar meses de trabalho de limpeza mais tarde.
O Perigo do Vazamento de Dados
Uma função crítica do pipeline é manter os dados de treinamento e teste separados. Se informações do conjunto de teste (por exemplo, sua distribuição geral) forem usadas para normalizar o conjunto de treinamento, o desempenho do seu modelo será artificialmente inflacionado e ele falhará no mundo real.
Fazendo a Escolha Certa para o Seu Objetivo
Sua abordagem para a estruturação de dados deve ser guiada por seu objetivo final.
- Se seu foco principal for a reprodutibilidade: Priorize governança de dados rígida e pipelines totalmente automatizados e com controle de versão desde o primeiro dia.
- Se seu foco principal for a prototipagem rápida: Comece com um pequeno conjunto de dados curado manualmente para validar sua abordagem de IA antes de investir em um pipeline em grande escala.
- Se seu foco principal for a expansão em uma grande organização: Invista pesadamente em armazenamento de dados centralizado, ontologias compartilhadas e componentes de pipeline comuns para evitar silos de dados.
Em última análise, tratar seus dados com o mesmo rigor que seus experimentos de laboratório úmido é a base para construir uma IA biológica bem-sucedida e confiável.
Tabela de Resumo:
| Etapa | Ação Principal | Propósito |
|---|---|---|
| Governança de Dados | Estabelecer convenções de nomenclatura, ontologias, padrões de metadados | Garantir consistência e comparabilidade entre os experimentos |
| Pipeline de Dados | Ingerir, analisar, CQ, normalizar, extrair características, montar | Automatizar a transformação de dados brutos em matriz de características prontas para IA |
| Compensações | Equilibrar superprocessamento vs. subprocessamento, gerenciar sobrecarga | Otimizar o desempenho do modelo e evitar vazamento de dados |
Com dificuldades para padronizar seus dados de laboratório úmido para IA? A KINTEK é especializada em máquinas de prensagem de laboratório, incluindo prensas de laboratório automáticas, prensas isostáticas e prensas de laboratório aquecidas, servindo laboratórios para aumentar a confiabilidade dos dados e a eficiência experimental. Deixe-nos ajudá-lo a alcançar resultados consistentes — entre em contato conosco hoje para discutir suas necessidades e descobrir como nossas soluções podem apoiar sua pesquisa orientada por IA!
Guia Visual